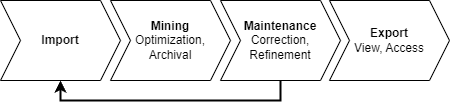
Structs Data Lifecycle
The XINA structs mnemonic data lifecycle involves four primary phases:
Source Files
Each origin maintains a set of source files, containing all data imported into XINA for that origin.
The primary type of source files are archive source files. Archive files are considered the definitive record of source data for a range of time for a single origin. These are stored in the XINA xbin binary file format. These are imported directly with the STRUCT ARCHIVE IMPORT action. Archive files are mined through the XINA Structs Mine task into XINA databases in order to be viewed in the XINA client, and are used to generate export packages.
Alternatively, an origin may use buffer source files. Buffer files may be imported in a variety of data formats and are not subject to the same strict requirements as archive files. These may are imported directly with the STRUCT BUFFER IMPORT action. Mnemonic data from buffer files is loaded into a temporary buffer database for immediate viewing in the XINA client. Buffer files are archived (merged and converted into archive files) through the XINA Structs Archive task, which can be run manually or configured to run in regular intervals. This is the recommended approach for importing mnemonic data when getting started with XINA Structs.
These come in two flavors, buffer source files and archive source files. . Buffer source files are an optional feature for less structured data inputs. Scheduled asynchronous tasks merge buffer files for each origin into archive files, allowing the buffer files to be deleted. In general, there are three supported approaches for origin data flow: buffer import, variable time archive import, and fixed time archive import. While a single origin may only support one workflow, a model may combine multiple workflows using multiple origins.
Buffer Import
The buffer import workflow is the most flexible mnemonic import method. Buffer files do not need to adhere to strict requirements (aside from conforming to standard accepted file formats). Buffer files for a given origin may have duplicated data, overlapping data, and can introduce new mnemonic definitions on demand.
Buffer files are imported with the STRUCT_BUFFER_IMPORT action. This invokes three effects:
- the raw buffer file is parsed, validated, and stored in the model origin buffer file database
- new mnemonic definitions are created for any unrecognized mnemonic labels
- data is added to the mnemonic buffer database for the associated origin
No additional data processing occurs as part of this step. XINA models utilizing buffer source files must implement routine execution of the STRUCT_BUFFER_ARCHIVE asynchronous task (typically every hour) to merge the files into archive files in a fixed-time archive format, which can then be processed by STRUCT_ARCHIVE_MINE tasks to fully process data into model standard databases.
Pros
- minimal client side configuration required to get started
- allows smaller, faster file uploads to view data close to real-time
- flexible and responsive to changing environments, mnemonics, requirements
Cons
- performance is worse than client side aggregation
- not recommended above 1k total data points per second
Buffer File Database
An origin must include a single buffer source file database to support buffer importing. Unlike the archive database, it is configured as single-file-per-record.
Required Fields
| Field | Type | Description |
|---|---|---|
uuid |
uuid |
universally unique ID |
name |
utf8vstring(128) |
file name |
t_import |
instant(us) |
time of file import |
t_min |
instant(us) |
earliest time of data in file |
t_max |
instant(us) |
latest time of data in file |
state |
struct_buffer_state |
current file state (see below) |
flag |
struct_buffer_flag |
file action flag (may be null) (see below) |
format |
asciivstring(16) |
file format (see below) |
conf |
jsonobject (may be null) |
configuration parameters, depending on format |
The state field may be one of four values:
-
PENDING- the file data is present in the mnemonic buffer database but has not been processed further -
PROCESSED- the file has not been converted into a standard xbin file format -
ARCHIVED- the file contents have been distributed to the appropriate archive file(s) -
DEPRECATED- the file is preserved but no longer included in archive files
The flag field may be one of two values:
-
DEPRECATE- the file is queued for deprecation -
DELETE- the file is queued for deletion
Buffer File Archive Task
The STRUCT_BUFFER_ARCHIVE task merges and compresses buffer files into archive files. This step is required to resolve any data discrepancies and ensure data is preserved in accordance with the requirements of archive files. The task performs the following steps:
- load all unprocessed files from the buffer file database
- for each time ranges affected by unprocessed files
- process each file into processed format
- load any existing processed files in those time ranges
- merge data from all processed files for time range into single archive file
- upload newly processed buffer files
- delete unprocessed buffer files
- upload merged archive file
- run mining task on merged archive file
- delete any mnemonic data already present for time range
- import mnemonic data generated by mining task
When the files are uploaded in the STRUCT_BUFFER_IMPORT action they must specify a merge mode, which determines how the data will be merged during the archive task. The process is intended to be iterative in order to easily trace the history of data.
ADD Mode
In "add" mode, data points from other files will not be affected unless they have the exact same combination of time and mnemonic parameters, in which case the most recently imported file value is used. This is the default mode.
REPLACE Mode
In "replace" mode, all data for all mnemonics in the file in the time range of the file (defined as the range from the earliest timestamp in the file to the latest timestamp in the file, inclusive) is replaced by the content of the file. This can be used to erase a range of data for a set of mnemonics by creating a file with a null data point for each mnemonic at a start time and end time.
REPLACE_ALL Mode
In "replace_all" mode, all data for all mnemonics in the time range of the file is replaced by the content of the file.
UUID Replacement
If a buffer file is imported with a UUID that is already associated with an existing buffer file, the new file is treated as an absolute replacement of the existing file, regardless of file content.
Direct Archive Import
Archive files are imported directly with the STRUCT_ARCHIVE_IMPORT API action, which triggers an immediate mining operation to store, index, and optimize data in XINA databases.
Pros
- much higher performance ceiling than server side aggregation
- stringent validation ensures data conforms to standard
Cons
- more complex initial setup
- mnemonic definitions must be pre-defined and cannot be added on-the-fly
- mnemonic definitions need coordination between client and server
- changes are more complex and likely involve human interaction
Variable-Time Archive Import
With variable-time archive import each archive specifies a custom time range. This is a recommended solution for projects which generate their own archival equivalent (for example, outputting a discrete data set after running a script). Because the time ranges are determined by the source data, the archive database for this approach includes all interval fields as well, to support handling the database as an interval database. It is configured as a multiple-file-per-record structure.
Required Fields
| Field | Type | Description |
|---|---|---|
uuid |
uuid |
universally unique ID |
p_id |
int(8) |
primary ID |
s_id |
int(8) |
secondary ID |
t_start |
instant(us) |
start time of data in file |
t_end |
instant(us) |
end time of data in file |
duration |
duration |
t_end - t_start |
t_min |
instant(us) |
earliest time of data in file |
t_max |
instant(us) |
latest time of data in file |
label |
utf8vstring(128) |
plain text label |
content |
utf8text |
extended text / CSV / HTML |
type |
int(2) |
interval type code |
level |
int(1) |
level code |
meta |
jsonobject (may be null) |
arbitrary metadata as needed |
format |
asciivstring(16) |
file format (see below) |
conf |
jsonobject (may be null) |
configuration parameters, depending on format |
Fixed-Time Archive Import
With fixed-time archive import each archive has a fixed time range. This is a recommended solution for projects which generate a persistent data stream (for example, data sources piped through a FEDS server). Unlike the variable-time archive database, this database is not treated as an interval database, because the time windows are arbitrary. It is configured as a multiple-file-per-record structure.
Required Fields
| Field | Type | Description |
|---|---|---|
uuid |
uuid |
universally unique ID |
t_start |
instant(us) |
start time of data in file |
t_end |
instant(us) |
end time of data in file |
duration |
duration |
t_end - t_start |
t_min |
instant(us) |
earliest time of data in file |
t_max |
instant(us) |
latest time of data in file |
meta |
jsonobject (may be null) |
arbitrary metadata as needed |
format |
asciivstring(16) |
file format (see below) |
conf |
jsonobject (may be null) |
configuration parameters, depending on format |
Source File Formats
Currently there are two natively supported general purpose formats, one using the codes csv/tsv (full documentation here), and a binary format using the code xbin (full documentation here) Additional formats will be added in the future, and custom project-specific formats may be added as needed.
Assumptions and Limitations
Each archive source file is considered the single source of truth for all mnemonics, instants, and intervals for it's associated origin for its time range. This has the following implications:
Archive files with the same origin cannot contain overlapping time ranges. If an import operation is performed with a file violating this constraint the operation will fail and return an error.
Within a single model, each mnemonic may only come from a single origin. Because mnemonics are not necessarily strictly associated with models, and the source may vary between models, this cannot be verified on import and must be verified on the client prior to importing data.