| field | type | description |
|---|---|---|
| `state` | `model_mn_state` | current state of mnemonic (`active`, `inactive`, `archived`, `deprecated`) |
| `origins` | `jsonobject` | map of model(s) to associated origin(s) |
| `full` | `asciivstring(32)` | the primary database for the mnemonic, default `f8` (may be `null`) |
| `bin` | `set(asciivstring(32))` | the opt-in bin database(s) to include the mnemonic in |
| `format` | `asciivstring(32)` | printf-style format to render values |
| `enum` | `jsonobject` | mapping of permitted text values to numeric values |
| `labels` | `list(jsonobject)` | mapping of numeric values or ranges to labels |
| `aliases` | `set(asciivstring(128))` | set of additional names associated with the mnemonic |
| `meta` | `jsonobject` | additional metadata as needed |
| `query` | `asciivstring(32)` | query name for meta-mnemonics (may be `null`) |
| `conf` | `jsonobject` | configuration for meta-mnemonics (may be `null`) |
| t | v |
|---|---|
| 0 | 0 |
| 1 | 0 |
| 2 | 0 |
| 3 | 1 |
| 4 | 1 |
| 5 | 1 |
| 6 | 1 |
| 7 | 2 |
| 8 | 2 |
| 9 | 2 |
| t | v | n |
|---|---|---|
| 0 | 0 | 2 |
| 2 | 0 | 1 |
| 3 | 1 | 3 |
| 6 | 1 | 1 |
| 7 | 2 | 2 |
| 9 | 2 | 1 |
| field | type | description | required |
|---|---|---|---|
| `t` | `instant` (matching model standard) | start time of the bin | yes |
| `t_min` | `instant` (matching model standard) | time of first data point in bin | yes |
| `t_max` | `instant` (matching model standard) | time of last data point in bin | yes |
| `mn_id` | `int(4)` | unique mnemonic ID | yes |
| `n` | `int(4)` | number of data points in bin | yes |
| `avg` | `float(8)` | average of points in bin | yes |
| `min` | `float(8)` | min of points in bin | yes |
| `max` | `float(8)` | max of points in bin | yes |
| `med` | `float(8)` | median of points in bin | no |
| `var` | `float(8)` | variance of points in bin | no |
| `std` | `float(8)` | standard deviation of points in bin | no |
| field | type | description | required |
|---|---|---|---|
| `t_start` | `instant(us)` | start time of the bin | yes |
| `t_end` | `instant(us)` | end time of the bin | yes |
| `dur` | `duration(us)` | duration | yes |
| `t_min` | `instant(us)` | time of first data point in bin | yes |
| `t_max` | `instant(us)` | time of last data point in bin | yes |
| `u_id` | `UUID` | UUID of associated interval | yes |
| `p_id` | `int(8)` | primary ID of associated interval | yes |
| `s_id` | `int(4)` | secondary ID of associated interval | yes |
| `mn_id` | `int(4)` | unique mnemonic ID | yes |
| `n` | `int(4)` | number of data points in bin | yes |
| `avg` | `float(8)` | average of points in bin | yes |
| `min` | `float(8)` | min of points in bin | yes |
| `max` | `float(8)` | max of points in bin | yes |
| `med` | `float(8)` | median of points in bin | no |
| `var` | `float(8)` | variance of points in bin | no |
| `std` | `float(8)` | standard deviation of points in bin | no |
| Code | Name | Ins | Int | Description |
|---|---|---|---|---|
| `0` | `message` | ✓ | ✓ | Basic event, ID optional |
| `1` | `marker` | ✓ | ✓ | Organized event, ID required |
| `2` | `alert` | ✓ | ✓ | Organized event, ID required, level (severity) required |
| `2000` | `test` | ✓ | Discrete test period, may not overlap other tests, ID optional | |
| `2001` | `activity` | ✓ | Discrete activity period, may not overlap other activities, ID optional | |
| `2002` | `phase` | ✓ | Discrete phase period, may not overlap other phases, ID optional | |
| `2010` | `filter` | ✓ | Filter state | |
| `3000` | `data` | ✓ | ✓ | General purpose data set |
| `3001` | `spectrum` | ✓ | ✓ | General purpose spectrum data |
| code | ins | int | description |
|---|---|---|---|
| `0-999` | ✓ | ✓ | General types for instants and intervals |
| `1000-1999` | ✓ | General types for instants only | |
| `2000-2999` | ✓ | General types for intervals only | |
| `3000-3999` | ✓ | ✓ | Data set types for instants and intervals |
| `4000-4999` | ✓ | Data set types for instants only | |
| `5000-5999` | ✓ | Data set types for intervals only |
| Key | Value | Default | Description |
|---|---|---|---|
| `delimiter` | `string` | auto detect (`','`, `'\t'`, `';'`) | value delimiter |
| `quoteChar` | `character` | `"` (double quote character) | value quote character |
| `ignoreLines` | `number` | `0` | number of lines to skip before the header |
| `invalid` | `null`, `'NaN'`, `number` | `null` | preferred interpretation of invalid literal |
| `nan` | `null`, `'NaN'`, `number` | `null` | preferred interpretation of `'Nan'` literal |
| `pInfinity` | `null`, `'Inf'`, `number` | `null` | preferred interpretation of positive `'Infinity'` literal |
| `nInfinity` | `null`, `'Inf'`, `number` | `null` | preferred interpretation of negative `'Infinity'` literal |
| `utc` | `boolean` | `false` | if `true`, interpret all unzoned timestamps as UTC |
| Unit | Description |
|---|---|
| `ts` | text timestamp, interpretted in local browser timezone (absent explicit zone) |
| `ts_utc` | text timestamp, interpretted as UTC timezone (absent explicit zone) |
| `unix_s` | Unix time in seconds |
| `unix_ms` | Unix time in milliseconds |
| `unix_us` | Unix time in microseconds |
| Key | Value | Default | Description |
|---|---|---|---|
| delimiter | string | `','` (comma character) | value delimiter |
| quote\_char | character | `"` (double quote character) | value quote character |
| ignore\_lines | number | `0` | lines to ignore at the start of the file |
| zone | string | UTC | time zone to use if not provided |
| values | JSON object | preferred interpretation of string literals (see below) |
| Name | Description | Alternate Names |
|---|---|---|
| **t** | Unix time or ISO8601 zoned timestamp | ts, time, timestamp, datetime, unix\_time, unix, utc |
| **k** | key | key, m, m\_id, mn, mn\_id, mnemonic, mnemonic\_id, n, name |
| **v** | value (numeric, empty, or `null`) | val, value |
| Code | Value | Length (bytes) | Description |
|---|---|---|---|
| `0` | `null` | 0 | literal `null` / empty string |
| `1` | ref dict index | 1 | index 0 to 255 (see below) |
| `2` | ref dict index | 2 | index 256 to 65,535 |
| `3` | ref dict index | 4 | index 65,536 to 2,147,483,647 |
| `4` | `true` | 0 | boolean literal |
| `5` | `false` | 0 | boolean literal |
| `6` | int1 | 1 | 1 byte signed integer |
| `7` | int2 | 2 | 2 byte signed integer |
| `8` | int4 | 4 | 4 byte signed integer |
| `9` | int8 | 8 | 8 byte signed integer |
| `10` | float4 | 4 | 4 byte floating point |
| `11` | float8 | 8 | 8 byte floating point |
| `12` | string1 | variable | seg1 UTF-8 encoded string |
| `13` | string2 | variable | seg2 UTF-8 encoded string |
| `14` | string4 | variable | seg4 UTF-8 encoded string |
| `15` | json1 | variable | seg1 UTF-8 encoded JSON |
| `16` | json2 | variable | seg2 UTF-8 encoded JSON |
| `17` | json4 | variable | seg4 UTF-8 encoded JSON |
| `18` | jsonarray1 | variable | seg1 UTF-8 encoded JSON array |
| `19` | jsonarray2 | variable | seg2 UTF-8 encoded JSON array |
| `20` | jsonarray4 | variable | seg4 UTF-8 encoded JSON array |
| `21` | jsonobject1 | variable | seg1 UTF-8 encoded JSON object |
| `22` | jsonobject2 | variable | seg2 UTF-8 encoded JSON object |
| `23` | jsonobject4 | variable | seg4 UTF-8 encoded JSON object |
| `24` | bytes1 | variable | seg1 raw byte array |
| `25` | bytes2 | variable | seg2 raw byte array |
| `26` | bytes4 | variable | seg4 raw byte array |
| `27` | xstring1 | variable | seg1 xstring |
| `28` | xstring2 | variable | seg2 xstring |
| `29` | xstring4 | variable | seg4 xstring |
| `30` | xjsonarray1 | variable | seg1 xjson array |
| `31` | xjsonarray2 | variable | seg2 xjson array |
| `32` | xjsonarray4 | variable | seg4 xjson array |
| `33` | xjsonobject1 | variable | seg1 xjson object |
| `34` | xjsonobject2 | variable | seg2 xjson object |
| `35` | xjsonobject4 | variable | seg4 xjson object |
| `36` - `255` | unusued, reserved |
| Code | Content (0 bytes) |
|---|---|
| `0x00` |
| Code | Content (2 bytes) |
|---|---|
| `0x07` | `0x01` `0x2c` |
| Code | Content (8 bytes) |
|---|---|
| `0x0b` | `0x3f` `0xce` `0xb8` `0x51` `0xEB` `0x85` `0x1E` `0xb8` |
| Code | Content (4 bytes) |
|---|---|
| `0x0c` | `0x03` `0x66` `0x6f` `0x6f` |
| Code | Content (14 bytes) |
|---|---|
| `0x0f` | `0x0d` `0x7b` `0x22` `0x66` `0x6f` `0x6f` `0x22` `0x3a` `0x22` `0x62` `0x61` `0x72` `0x22` `0x7d` |
| Code | Content (7 bytes) |
|---|---|
| `0x1b` | \[ `0x06` \](total length) \[ `0x03` `0x66` `0x6f` `0x6f` \]("foo") \[ `0x04` `0x7b` \](123) |
| t | voltage | current | label |
|---|---|---|---|
| 0 | 5 | 10 | "foo" |
| 1 | "bar" | ||
| 2 | 5 | null |
| Key | Required | Description |
|---|---|---|
| dir | ✓ | The path to the dir containing the archive file and any ancillary files needed for processing |
| dest | ✓ | The path to the dir that all output (e.g. `xbin` file) should be placed |
| mission | ✓ | TBC: The mission which may be needed to determine how the archive file is processed |
| model | ✓ | TBC: The mission's model which may be needed to determine how the archive file is processed |
| raw | The mnemonic IDs of the mnemonics that should be extracted and output, unconverted | |
| eng | The mnemonic IDs of the mnemonics that should be extracted and output with the engineering conversion applied | |
| sci | The mnemonic IDs of the mnemonics that should be extracted and output with the science conversion applied | |
| time\_mode | For projects that support it, defines which time source should be used when timestamping the mnemonic data. Either "pkt" or "grt" (ground receipt time). If not provided, it should default to packet time. |
| Name | Code | Description |
|---|---|---|
| Success | 0 | Execution was successful |
| Error | 1 | Generic error code for unsuccessful execution. A more specific error code should be preferred over this one. |
| Finished with warnings | 3 | Execution finished but there were warnings. The log file should be examined for more info |
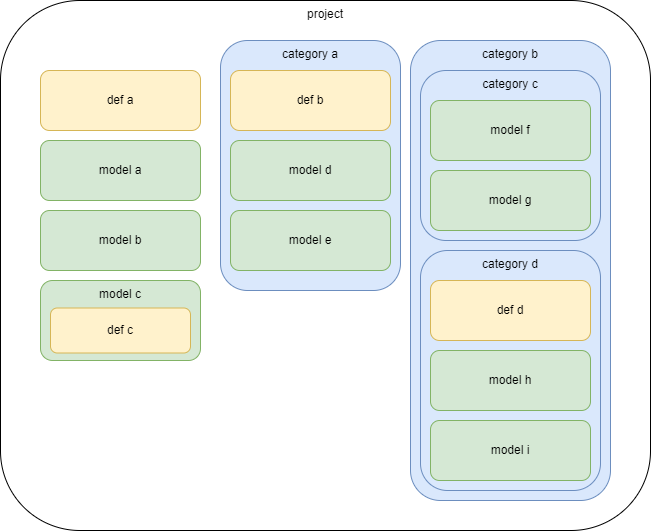
| Parameter | Value |
|---|---|
| type | `"project"` |
| Parameter | Value |
|---|---|
| name | \* |
| label | \* |
| Parameter | Value |
|---|---|
| type | `"category"` |
| Parameter | Value |
|---|---|
| name | \* |
| label | \* |
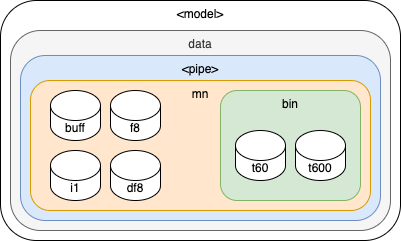
| Parameter | Value |
|---|---|
| type | `"model"` |
| Parameter | Value |
|---|---|
| name | \* |
| label | \* |
| Parameter | Value | Default |
|---|---|---|
| type | `"pipe"` |
| Parameter | Value | Default |
|---|---|---|
| discrete | boolean | `false` |
| buffer | boolean | `false` |
| variable | boolean | `false` |
| condense | boolean | `false` |
| duration | archive length in minutes | `60` |
| partition | `{"from": |
| Parameter | Value |
|---|---|
| name | \* |
| label | \* |
| Parameter | Value |
|---|---|
| type | `"def"` |
| Parameter | Value |
|---|---|
| name | `"def"` |
| label | `"Definitions"` |
| Parameter | Value |
|---|---|
| type | `"task"` |
| Parameter | Value |
|---|---|
| name | `"task"` |
| label | `"Task"` |
| Parameter | Value |
|---|---|
| type | `"mn"` |
| Parameter | Value |
|---|---|
| name | `"mn"` |
| label | `"Mnemonic"` |
| Parameter | Value |
|---|---|
| type | `"mn_bin"` |
| Parameter | Value |
|---|---|
| name | `"bin"` |
| label | `"Bin"` |
| Parameter | Value |
|---|---|
| type | `"def_diagram"` |
| Parameter | Value |
|---|---|
| name | `"diagram"` |
| label | `"Diagram"` |
| format | `"{name}"` |
| order | (`name`, desc) |
| singular | `"diagram"` |
| Name | Type | Req | Description |
|---|---|---|---|
| name | `utf8vstring(128)` | ✓ | unique conf name |
| desc | `utf8text` | plain text description | |
| file\_name | `utf8filename` | ✓ | file name |
| conf | `jsonobject` | diagram configuration | |
| meta | `jsonobject` | additional metadata as needed |
| Parameter | Value |
|---|---|
| type | `"def_event"` |
| Parameter | Value |
|---|---|
| name | `"event"` |
| label | `"Event"` |
| format | `"{name}"` |
| order | (`name`, asc) |
| singular | `"event definition"` |
| Name | Type | Req | Description |
|---|---|---|---|
| e\_id | `int(4)` | ✓ | unique ID |
| name | `utf8vstring(128)` | ✓ | unique name |
| desc | `utf8text` | plain text description | |
| meta | `jsonobject` | additional arbitrary metadata | |
| conf | `jsonobject` | configuration for pseudo-events | |
| aliases | `set(utf8string)` | alternative name(s) | |
| ext\_id | `asciivstring(64)` | external ID |
| Name | Type | Req | Description |
|---|---|---|---|
| type | `utf8vstring(128)` | ✓ | Must have a value of "filter" |
| condition | `utf8text` | ✓ | filter condition expression |
| t\_start\_offset | `duration(us)` | start time offset (`0` if not provided) | |
| t\_end\_offset | `duration(us)` | end time offset (`0` if not provided) | |
| models | `set(asciistring)` | Models that the filter will apply to |
| Parameter | Value |
|---|---|
| type | `"def_mn"` |
| Parameter | Value |
|---|---|
| name | `"mn"` |
| label | `"Mnemonic"` |
| format | `"{name} ({unit})"` |
| order | (`name`, asc) |
| singular | `"mnemonic definition"` |
| Name | Type | Req | Description |
|---|---|---|---|
| mn\_id | `int(4)` | ✓ | unique mnemonic ID |
| name | `utf8vstring(128)` | ✓ | unique mnemonic name |
| subname | `utf8vstring(32)` | mnemonic sub-name | |
| desc | `utf8text` | plain text mnemonic description | |
| unit | `utf8vstring(32)` | measurement unit (for example, `"V"`, `"mA"`) | |
| state | `struct_mn_state` | ✓ | current state of mnemonic |
| pipes | `jsonobject` | ✓ | map of model(s) to associated pipe(s) |
| full | `asciivstring(32)` | the primary database for the mnemonic, default `f8` | |
| bin | `set(asciistring)` | the opt-in bin database(s) to include the mnemonic in | |
| format | `asciivstring(32)` | printf-style format to render values | |
| enums | `jsonobject` | mapping of permitted text values to numeric values | |
| labels | `list(jsonobject)` | mapping of numeric values or ranges to labels | |
| aliases | `set(utf8string)` | set of additional names associated with the mnemonic | |
| meta | `jsonobject` | additional metadata as needed | |
| query | `asciivstring(32)` | query name for pseudo-mnemonics | |
| conf | `jsonobject` | configuration for pseudo-mnemonics | |
| ext\_id | `asciistring` | external ID |
| Parameter | Value |
|---|---|
| type | `"def_mn_track"` |
| Parameter | Value |
|---|---|
| name | `"mn_track"` |
| label | `"Mnemonic Tracking"` |
| format | `"{t} {mn_id} {user}"` |
| order | (`name`, asc) |
| singular | `"mnemonic definition"` |
| Name | Type | Req | Description |
|---|---|---|---|
| t | `instant(us)` | ✓ | time of selection |
| mn\_id | `int(4)` | ✓ | mnemonic ID selected |
| user | `user_id` | ✓ | user taking action |
| mns | `set(int(4))` | other mnemonic ID(s) selected | |
| models | `set(asciistring)` | model(s) in current context |
| Parameter | Value |
|---|---|
| type | `"def_nominal"` |
| Parameter | Value |
|---|---|
| name | `"nominal"` |
| label | `"Nominal"` |
| format | `"{mn_id} {color} ({min}, {max}) {label}"` |
| order | (`mn_id`, asc), (`label`, asc) |
| singular | `"nominal definition"` |
| Name | Type | Req | Description |
|---|---|---|---|
| unid | `uuid` | ✓ | unique nominal range ID |
| mn\_id | `int(4)` | ✓ | unique mnemonic ID |
| label | `utf8vstring(128)` | ✓ | nominal range label |
| desc | `utf8text` | plain text nominal range description | |
| color | `struct_nominal_color` | range color indicator | |
| min | `float(8)` | min value for the range | |
| max | `float(8)` | max value for the range | |
| models | `set(asciistring)` | models for which this range should apply (all if `null`) | |
| meta | `jsonobject` | additional metadata as needed |
| Parameter | Value |
|---|---|
| type | `"def_plot"` |
| Parameter | Value |
|---|---|
| name | `"plot"` |
| label | `"Plot Conf"` |
| format | `"{name}"` |
| order | (`name`, asc) |
| singular | `"plot configuration"` |
| Name | Type | Req | Description |
|---|---|---|---|
| name | `utf8vstring(128)` | ✓ | unique conf name |
| desc | `utf8text` | plain text conf description | |
| plot\_conf | `struct_plot_conf` | ✓ | configuration |
| models | `set(asciistring)` | models for which this conf should apply (any if `null`) |
| Parameter | Value |
|---|---|
| type | `"def_profile"` |
| Parameter | Value |
|---|---|
| name | `"profile"` |
| label | `"Profile"` |
| format | `"{name}"` |
| order | (`name`, asc) |
| singular | `"profile"` |
| Name | Type | Req | Description |
|---|---|---|---|
| name | `utf8vstring(128)` | ✓ | unique profile name |
| desc | `utf8text` | plain text profile description | |
| models | `set(asciistring)` | models for which this conf should apply (all if `null`) | |
| data\_conf | `struct_data_conf` | ✓ | profile data configuration |
| plot\_conf | `struct_plot_conf` | profile plot configuration. If not provided, defaults to 1 mnemonic per plot, 1 plot per page. | |
| auto\_confs | `list(struct_auto_conf)` | automation configuration |
| Name | Type | Req | Description |
|---|---|---|---|
| ids | `utf8text` | CSV range list of `mn_id`s e.g. `"1,2-10,100"` or `ext_id` formatted string e.g. `"@[1,4-8,12,100-200]sci;@[2,3]raw"` | |
| filter | `jsonarray` of filter `jsonobject`s | List of filters to apply. Each filter object may reference an existing filter by name using the `filter` key, or directly provide a [filter definition](https://wiki.xina.io/link/170#bkmrk-filter-conf-jsonobje) (the `type` and `models` fields are ignored). An `ids` key can be used to define which mnemonics the filter should apply to. If `ids` is not provided, then the filter will be applied to every mnemonic. Only one filter per mnemonic is currently supported. | |
| limit | `boolean` | If `True`, generate the Limit Report. Defaults to `False`. | |
| pkt | `boolean` | If `True`, export using Packet Time instead of Ground Receipt Time. Defaults to `False`. Ignored if the archives only contain 1 time source. | |
| join | `boolean` | If `True`, the data file will be formatted with 1 unique time per row, and 1 mnemonic per column. Defaults to `False`. | |
| fill | `boolean` | If `True` and `join` is `True`, empty cells will be populated with the most recent value. Defaults to `False`. | |
| dis | `boolean` | If `True`, each mnemonic will also be exported using the Discrete conversion, if available. Defaults to `False`. | |
| columns | `jsonobject` | Defines which columns are included in the data file. |
| Name | Type | Req | Description |
|---|---|---|---|
| date\_utc | `boolean` | ||
| ts\_utc\_iso | `boolean` | ||
| ts\_utc\_excel | `boolean` | ||
| ts\_utc\_excel\_ms | `boolean` | ||
| ts\_utc\_doy | `boolean` | ||
| t\_utc\_unix\_s | `boolean` | ||
| t\_utc\_unix\_ms | `boolean` | ||
| t\_utc\_unix\_us | `boolean` | ||
| date\_tai | `boolean` | ||
| ts\_tai\_iso | `boolean` | ||
| ts\_tai\_doy | `boolean` | ||
| t\_tai\_unix\_s | `boolean` | ||
| t\_tai\_unix\_ms | `boolean` | ||
| t\_tai\_unix\_us | `boolean` | ||
| t\_tai\_tai\_s | `boolean` | ||
| t\_tai\_tai\_ms | `boolean` | ||
| t\_tai\_tai\_us | `boolean` | ||
| t\_rel\_s | `boolean` | ||
| t\_rel\_ms | `boolean` | ||
| t\_rel\_us | `boolean` | ||
| name | `boolean` | ||
| unit | `boolean` |
| Name | Type | Req | Description |
|---|---|---|---|
| daily | `boolean` | If `True`, the Profile will be exported once per day. Defaults to `False`. | |
| mine | `boolean` | If `True`, the Profile will be exported during the Mining Task when any of the defined `intervals` are processed. | |
| users | `set(utf8vstring(128))` | The list of NASA AUIDs to notify via email when the Daily Profile Export is generated |
| Parameter | Value |
|---|---|
| type | `"def_trend"` |
| Parameter | Value |
|---|---|
| name | `"trend"` |
| format | `"Trend"` |
| order | (`name`, asc) |
| singular | `"trend definition"` |
| Name | Type | Req | Description |
|---|---|---|---|
| name | `utf8vstring(128)` | ✓ | unique trend name |
| desc | `utf8text` | plain text trend description | |
| profiles | `set(utf8string)` | ✓ | profile name(s) to include in trend |
| models | `set(asciistring)` | models for which this trend should apply (any if `null`) | |
| trend\_conf | `struct_trend_conf` | trend configuration | |
| plot\_conf | `jsonobject` | Mapping of profile name to `struct_plot_conf` objects, alllowing you to override a Profile's plot conf. | |
| auto\_conf | `struct_auto_conf` | automated generation configuration |
| Name | Type | Req | Description |
|---|---|---|---|
| bin\_size | `int(4)` | The bin size in minutes to use when trending time ranges | |
| bin\_count | `int(4)` | Multiplier of the `bin_size` to use when trending time ranges. The actual trended bin size in minutes is `bin_size` \* `bin_count`. | |
| t | array of time range JSON objects | List of JSON objects describing time ranges to trend e.g. `{"start": "2021-06-30T00:00:00Z", "end": "2021-07-21T00:00:00Z" }` | |
| intervals | array of interval JSON objects | List of JSON objects describing Event Intervals to trend | |
| disable\_filter | `boolean` | If `True`, do not use any filtered data. Defaults to `False`. |
| Name | Type | Req | Description |
|---|---|---|---|
| daily | `boolean` | If `True`, the Trend will be generated once per day. Defaults to `False`. | |
| mine | `boolean` | If `True`, the Trend will be generated during the Mining Task when either the Time Range or Interval condition is satisfied. | |
| users | `set(utf8vstring(128))` | The list of NASA AUIDs to notify via email when the Daily Trend is generated |
| Parameter | Value |
|---|---|
| type | `"file_archive"` |
| Parameter | Value |
|---|---|
| name | `"archive"` |
| label | `"Archive"` |
| format | `"{t_start} {t_end}"` |
| singular | `"archive file"` |
| Name | Type | Req | Description |
|---|---|---|---|
| a\_id | `int(4)` | ✓ | archive ID |
| ufid | `uuid` | ✓ | file UUID |
| t\_start | `instant(us)` | ✓ | start time of the time range that the file covers |
| t\_end | `instant(us)` | ✓ | end time of the time range that the file covers, not inclusive |
| dur | `duration(us)` | ✓ | **virtual** `t_end` - `t_start` |
| t\_min | `instant(us)` | ✓ | time of first data in file |
| t\_max | `instant(us)` | ✓ | time of last data in file |
| file\_name | `utf8filename` | ✓ | archive file name |
| meta | `jsonobject` | additional metadata as needed | |
| format | `asciivstring(32)` | file format: `xbin` or `xpf`, where `xpf` is a zipped dir (default `xbin`) | |
| conf | `jsonobject` | configuration for format as needed |
| Parameter | Value |
|---|---|
| type | `"file_buffer"` |
| Parameter | Value |
|---|---|
| name | `"buffer"` |
| label | `"Buffer"` |
| format | `"{file_name}"` |
| singular | `"buffer file"` |
| Name | Type | Req | Description |
|---|---|---|---|
| ufid | `uuid` | ✓ | file UUID |
| file\_name | `utf8filename` | ✓ | buffer file name |
| t\_min | `instant(us)` | ✓ | time of first data in file |
| t\_max | `instant(us)` | ✓ | time of last data in file |
| dur | `duration(us)` | ✓ | **virtual** `t_max` - `t_min` |
| state | `struct_buffer_state` | ✓ | buffer file state |
| flag | `struct_buffer_flag` | buffer file flag | |
| meta | `jsonobject` | additional metadata as needed | |
| format | `asciivstring(32)` | buffer file format (default `"csv"`) | |
| conf | `jsonobject` | configuration for format as needed |
| Parameter | Value |
|---|---|
| type | `"file_cft"` |
| Parameter | Value |
|---|---|
| name | `"cft"` |
| label | `"CFT"` |
| format | `"{file_name}"` |
| singular | `"CFT file"` |
| Name | Type | Req | Description |
|---|---|---|---|
| a\_id | `int(4)` | ✓ | archive ID |
| ufid | `uuid` | ✓ | file UUID |
| file\_name | `utf8filename` | ✓ | CVT file name |
| format | `asciivstring(32)` | CVT file format (default `"csv"`) | |
| conf | `jsonobject` | configuration for format as needed |
| Parameter | Value |
|---|---|
| type | `"file_cvt"` |
| Parameter | Value |
|---|---|
| name | `"cvt"` |
| label | `"CVT"` |
| format | `"{file_name}"` |
| singular | `"CVT file"` |
| Name | Type | Req | Description |
|---|---|---|---|
| a\_id | `int(4)` | ✓ | archive ID |
| ufid | `uuid` | ✓ | file UUID |
| file\_name | `utf8filename` | ✓ | CVT file name |
| meta | `jsonobject` | additional metadata as needed | |
| format | `asciivstring(32)` | CVT file format (default `"csv"`) | |
| conf | `jsonobject` | configuration for format as needed |
| Parameter | Value |
|---|---|
| type | `"file_package"` |
| Parameter | Value |
|---|---|
| name | `"package"` |
| label | `"Package"` |
| format | `"{file_name}"` |
| singular | `"package file"` |
| Name | Type | Req | Description |
|---|---|---|---|
| t\_start | `instant(us)` | ✓ | start time |
| t\_end | `instant(us)` | ✓ | end time |
| a\_id | `int(4)` | archive ID (if generated automatically) | |
| ueid | `UUID` | UEID, if time range from event | |
| label | `utf8vstring(128)` | ✓ | package label |
| file\_name | `utf8filename` | ✓ | package file name |
| data\_conf | `struct_data_conf` | ✓ | data configuration |
| plot\_conf | `struct_plot_conf` | plot configuration | |
| auto\_conf | `struct_auto_conf` | automation configuration | |
| profile | `utf8vstring(128)` | profile name, if profile used | |
| profile\_version | `int(4)` | profile version, if profile used | |
| meta | `jsonobject` | additional metadata as needed |
| Parameter | Value |
|---|---|
| type | `"file_trend"` |
| Parameter | Value |
|---|---|
| name | `"trend"` |
| label | `"Trend"` |
| format | `"{file_name}"` |
| singular | `"trend file"` |
| Name | Type | Req | Description |
|---|---|---|---|
| name | `utf8vstring(128)` | ✓ | Name of Trend Definition used to generate the Trend Package |
| desc | `utf8text` | ✓ | Description of Trend Definition used to generate the Trend Package |
| profiles | `set(utf8string)` | ✓ | Profiles included in the Trend Package |
| trend\_conf | `struct_trend_conf` | ✓ | Trend Definition's trend conf used to generate the Trend Package |
| plot\_conf | `struct_plot_conf` | ✓ | Trend Definition's plot conf used to generate the Trend Package |
| file\_name | `utf8filename` | ✓ | The filename of the Trend Package zip file |
| meta | `jsonobject` | ✓ | Metadata |
| t\_min | `instant(us)` | ✓ | Time of the earliest bin point used in the trend |
| t\_max | `instant(us)` | ✓ | Time of the latest bin point used in the trend |
| generated\_at | `instant(us)` | ✓ | Datetime when the Trend Package was generated |
| generated\_by | `user_id` | ✓ | ID of user that generated the Trend Package |
| Parameter | Value |
|---|---|
| type | `"event"` |
| Parameter | Value |
|---|---|
| name | \* (default `"event"`) |
| label | \* (default `"Event"`) |
| format | \* (default `"{t_start} {event_id} {label}"`) |
| order | \* (default (`t_start`, desc), (`event_id`, asc)) |
| singular | \* (default `"event"`) |
| Name | Type | Req | Virtual | Description |
|---|---|---|---|---|
| ueid | `uuid` | ✓ | event UUID | |
| e\_id | `int(4)` | ✓ | event ID (default to `0` if not provided) | |
| a\_id | `int(4)` | ✓ | archive ID (only present if child of a pipe group) | |
| t\_start | `instant(us)` | ✓ | start time | |
| t\_end | `instant(us)` | end time, not inclusive (if `null`, event is an open interval) | ||
| dur | `duration(us)` | ✓ | ✓ | duration in microseconds (`null` if open) |
| interval | `boolean` | ✓ | ✓ | `t_start` != `t_end` |
| open | `boolean` | ✓ | ✓ | `t_end` is `null` |
| type | [struct\_event\_type](https://wiki.xina.io/link/74#bkmrk-types) | ✓ | event type (default to `message` if not provided) | |
| level | `struct_event_level` | ✓ | event level (default to `none` if not provided) | |
| label | `utf8vstring(128)` | ✓ | plain text label | |
| content | `utf8text` | extended event content | ||
| meta | `jsonobject` | additional metadata as needed | ||
| conf | `jsonobject` | configuration for specific event types |
| Parameter | Value |
|---|---|
| name | \* (default `"eventf"`) |
| label | \* (default `"Event File"`) |
| singular | \* (default `"event file"`) |
| Name | Type | Req | Description |
|---|---|---|---|
| file\_name | `utf8filename` | ✓ | file name |
| Parameter | Value |
|---|---|
| name | \* (default `"eventfs"`) |
| label | \* (default `"Event Files"`) |
| singular | \* (default `"event files"`) |
| Parameter | Value |
|---|---|
| type | `"event_update"` |
| Parameter | Value |
|---|---|
| name | `"{name}_update"`) |
| label | `"{label} Update"` |
| format | `"{t_start} {ueid} {label}"`) |
| order | (`t`, desc) |
| singular | `"event change"` |
| Name | Type | Req | Description |
|---|---|---|---|
| t | `instant(us)` | ✓ | event change time |
| ueid | `uuid` | ✓ | event UUID |
| update | `jsonobject` | ✓ | field(s) to update |
| Parameter | Value |
|---|---|
| type | `"mn_buffer"` |
| Parameter | Value |
|---|---|
| name | `"buffer"` |
| label | `"Buffer"` |
| format | `"{t} {mn_id} {v}"` |
| singular | `"mnemonic buffer datapoint"` |
| Name | Type | Req | Description |
|---|---|---|---|
| t | `instant(us)` | ✓ | time |
| mn\_id | `int(4)` | ✓ | unique mnemonic ID |
| v | `{conf.type}` | value |
| Parameter | Value |
|---|---|
| type | `"mn_full"` |
| Parameter | Value | Default |
|---|---|---|
| type | `"int(1)"`, `"int(2)"`, `"int(4)"`, `"int(8)"`, `"float(4)"`, or `"float(8)"` | `"float(8)"` |
| Parameter | Value |
|---|---|
| name | `"i1"`, `"i2"`, `"i4"`, `"i8"`, `"f4"`, or `"f8"` |
| label | `"Full |
| format | `"{t} {mn_id} {v}"` |
| singular | `"mnemonic datapoint"` |
| Name | Type | Req | Description |
|---|---|---|---|
| a\_id | `int(4)` | ✓ | archive ID |
| t | `instant(us)` | ✓ | time |
| mn\_id | `int(4)` | ✓ | unique mnemonic ID |
| v | `{conf.type}` | value |
| Parameter | Value |
|---|---|
| type | `"mn_delta"` |
| Parameter | Value | Default |
|---|---|---|
| type | `"int(1)"`, `"int(2)"`, `"int(4)"`, `"int(8)"`, `"float(4)"`, or `"float(8)"` | `"float(8)"` |
| Parameter | Value |
|---|---|
| name | `"di1"`, `"di2"`, `"di4"`, `"di8"`, `"df4"`, or `"df8"` |
| label | `"Delta {conf.type}"` |
| format | `"{t} {mn_id} {v} ({n})"` |
| singular | `"mnemonic delta datapoint"` |
| Name | Type | Req | Description |
|---|---|---|---|
| a\_id | `int(4)` | ✓ | archive ID |
| t | `instant(us)` | ✓ | time |
| mn\_id | `int(4)` | ✓ | unique mnemonic ID |
| v | `{conf.type}` | value | |
| n | `int(4)` | ✓ | number of datapoints included in this point |
| Parameter | Value |
|---|---|
| type | `"mn_bin_time"` |
| Parameter | Value |
|---|---|
| t | bin size in seconds |
| Parameter | Value |
|---|---|
| name | `"t |
| label | `"Time ( |
| format | `"{t} {mn_id} {avg} ({min}, {max})"` |
| singular | `"mnemonic bin"` |
| Name | Type | Req | Description |
|---|---|---|---|
| a\_id | `int(4)` | ✓ | archive ID |
| t | `instant(us)` | ✓ | start time of the bin |
| mn\_id | `int(4)` | ✓ | unique mnemonic ID |
| t\_min | `instant(us)` | ✓ | time of first datapoint |
| t\_max | `instant(us)` | ✓ | time of last datapoint |
| n | `int(4)` | ✓ | number of datapoints in bin |
| avg | `float(8)` | ✓ | average |
| min | `float(8)` | ✓ | min |
| max | `float(8)` | ✓ | max |
| std | `float(8)` | ✓ | sample standard deviation |
| Parameter | Value |
|---|---|
| type | `"mn_bin_interval"` |
| Parameter | Value |
|---|---|
| name | `"interval"` |
| label | `"Interval"` |
| format | `"{t} {e_id} {mn_id} {avg} ({min}, {max})"` |
| singular | `"mnemonic bin"` |
| Name | Type | Req | Description |
|---|---|---|---|
| a\_id | `int(4)` | ✓ | archive ID |
| ueid | `uuid` | ✓ | |
| e\_id | `int(8)` | ✓ | |
| t\_start | `instant(us)` | ✓ | start time |
| t\_end | `instant(us)` | ✓ | end time |
| mn\_id | `int(4)` | ✓ | unique mnemonic ID |
| t\_min | `instant(us)` | ✓ | time of first datapoint |
| t\_max | `instant(us)` | ✓ | time of last datapoint |
| n | `int(4)` | ✓ | number of datapoints in bin |
| avg | `float(8)` | ✓ | average |
| min | `float(8)` | ✓ | min |
| max | `float(8)` | ✓ | max |
| std | `float(8)` | sample standard deviation |
| Parameter | Value |
|---|---|
| type | `"mn_bin_edge"` |
| Parameter | Value |
|---|---|
| name | `"edge"` |
| label | `"Edge"` |
| format | `"{t_start} - {t_end} {mn_id} {avg} ({min}, {max})"` |
| singular | `"mnemonic bin"` |
| Name | Type | Req | Description |
|---|---|---|---|
| a\_id | `int(4)` | ✓ | archive ID |
| t\_start | `instant(us)` | ✓ | start time |
| t\_end | `instant(us)` | ✓ | end time |
| mn\_id | `int(4)` | ✓ | unique mnemonic ID |
| t\_min | `instant(us)` | ✓ | time of first datapoint |
| t\_max | `instant(us)` | ✓ | time of last datapoint |
| n | `int(4)` | ✓ | number of datapoints in bin |
| avg | `float(8)` | ✓ | average |
| min | `float(8)` | ✓ | min |
| max | `float(8)` | ✓ | max |
| std | `float(8)` | ✓ | sample standard deviation |
| Parameter | Value |
|---|---|
| type | task\_condense |
| Parameter | Value |
|---|---|
| name | `"condense"` |
| label | `"Condense"` |
| format | `"{task_id} {t}"` |
| singular | `"condense task"` |
| Name | Type | Req | Description |
|---|---|---|---|
| task\_id | `task_id` | ✓ | unique task ID |
| t | `instant(us)` | ✓ | time when task submitted |
| meta | `jsonobject` | additional metadata as needed | |
| conf | `jsonobject` | task configuration | |
| condensed | `list(jsonobject)` | buffer file(s) condensed |
| Parameter | Value |
|---|---|
| type | task\_mine |
| Parameter | Value |
|---|---|
| name | `"mine"` |
| label | `"Mine"` |
| format | `"{task_id} {t_start}"` |
| singular | `"mine task"` |
| Name | Type | Req | Description |
|---|---|---|---|
| task\_id | `task_id` | ✓ | unique task ID |
| t | `instant(us)` | ✓ | time when task submitted |
| ufid | `uuid` | ✓ | source archive file UUID |
| t\_start | `instant(us)` | ✓ | source archive file start time |
| t\_end | `instant(us)` | ✓ | source archive file end time |
| meta | `jsonobject` | additional metadata as needed | |
| conf | `jsonobject` | task configuration |
| Parameter | Value |
|---|---|
| type | task\_archive |
| Parameter | Value |
|---|---|
| name | `"archive"` |
| label | `"Archive"` |
| format | `"{task_id} {t}"` |
| singular | `"archive task"` |
| Name | Type | Req | Description |
|---|---|---|---|
| task\_id | `task_id` | ✓ | unique task ID |
| t | `instant(us)` | ✓ | time when task submitted |
| meta | `jsonobject` | additional metadata as needed | |
| conf | `jsonobject` | task configuration | |
| archives | `list(jsonobject)` | archives updated | |
| archived | `list(jsonobject)` | buffer file(s) archived | |
| restored | `list(jsonobject)` | buffer file(s) restored | |
| deprecated | `list(jsonobject)` | buffer file(s) deprecated | |
| deleted | `list(jsonobject)` | buffer file(s) deleted |
| Property | Value | Req | Description |
|---|---|---|---|
| tabs | array of tab conf(s) | custom tabs for UI | |
| presearch | array of presearch confs | custom pre-search components for UI | |
| filters | array of filter confs | ||
| grouping | array of field name(s) | ||
| charts | charts conf | ✓ | |
| tables | array of table conf | ||
| query | query conf | ||
| labels | labels conf |
| Property | Value | Req | Description |
|---|---|---|---|
| type | `"database"` | ✓ | tab type name |
| database | database specifier | ✓ | target database specifier |
| map | see below | ✓ | solution to map target selection to spectra selection |
| Property | Value | Req | Description |
|---|---|---|---|
| type | `"field"` | ✓ | presearch type name |
| field | field specifier | ✓ | |
| options | see below | options for search dropdown |
| Property | Value | Req | Description |
|---|---|---|---|
| name | `string` | ✓ | system name for filter |
| label | `string` | display label (uses name if absent) | |
| badge | `string` | badge label (uses name if absent) | |
| desc | `string` | description for badge / filter tooltip | |
| color | `string` | color code or CSS class | |
| e | `expression` | ✓ | expression to apply for filter |
| Property | Value | Req | Description |
|---|---|---|---|
| summary | spectra chart conf | ✓ | summary chart conf |
| spectra | spectra chart conf | ✓ | spectra chart conf |
| Property | Value | Req | Description |
|---|---|---|---|
| x | `string[]` | ✓ | x axis options |
| y | `string[]` | ✓ | y axis options |
| tooltip | `string` | record format string |