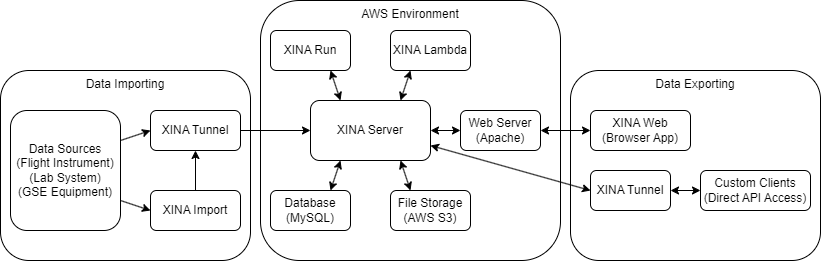
| Type | Java | MySQL | JavaScript | Notes |
|---|---|---|---|---|
| `int(1)` | `byte` | `tinyint` | `number` | 1 byte signed integer, -27 to 27-1 |
| `int(2)` | `short` | `smallint` | `number` | 2 byte signed integer, -215 to 215-1 |
| `int(4)` | `int` | `int` | `number` | 4 byte signed integer, -231 to 231-1 |
| `int(8)` | `long` | `bigint` | `number` | 8 byte signed integer, -263 to 263-1 ⚠️ |
| Type | Java | MySQL | JavaScript | Notes |
|---|---|---|---|---|
| `float(4)` | `float` | `float` | `number` | IEEE 754 4 byte floating point |
| `float(8)` | `double` | `double` | `number` | IEEE 754 8 byte floating point |
| Type | Java | MySQL | JavaScript |
|---|---|---|---|
| `boolean` | `boolean` | `tinyint` | `boolean` |
| Type | Java | MySQL | JavaScript | Notes |
|---|---|---|---|---|
| `utf8string(n)` | `string` | `char(n)` | `string` | n up to 128, uses `n*4` bytes, normalized |
| `utf8vstring(n)` | `string` | `varchar(n)` | `string` | n up to 128, uses up to `n*4` bytes, normalized |
| `utf8string` | `string` | `mediumtext` | `string` | up to 224 bytes, normalized |
| `utf8text` | `string` | `mediumtext` | `string` | up to 224 bytes, not normalized |
| `utf8filename` | `string` | `varchar(255)` | `string` | uses up to 255 bytes, file-safe characters only |
| `asciistring(n)` | `string` | `char(n)` | `string` | n up to 256, uses n bytes, normalized |
| `asciivstring(n)` | `string` | `varchar(n)` | `string` | n up to 256, uses up to n bytes, normalized |
| `asciistring` | `string` | `mediumtext` | `string` | up to 224 bytes, normalized |
| `asciitext` | `string` | `mediumtext` | `string` | up to 224 bytes, not normalized |
| `asciifilename` | `string` | `varchar(255)` | `string` | uses up to 255 bytes, file-safe characters only |
| Type | Java | MySQL | JavaScript |
|---|---|---|---|
| `instant(s)` | `DateTime` | `bigint` | `date` |
| `instant(ms)` | `DateTime` | `bigint` | `date` |
| `instant(us)` | `DateTime` | `bigint` | `date` |
| Type | Java | MySQL | JavaScript |
|---|---|---|---|
| `date(s)` | `XDate` | `bigint` | `date` |
| `date(ms)` | `XDate` | `bigint` | `date` |
| `date(us)` | `XDate` | `bigint` | `date` |
| `time(s)` | `LocalTime` | `int` | `number` |
| `time(ms)` | `LocalTime` | `int` | `number` |
| `time(us)` | `LocalTime` | `bigint` | `number` |
| Type | Java | MySQL | JavaScript | Notes |
|---|---|---|---|---|
| `datetime` | `DateTime` | `bigint` | `date` | replaced by `instant(ms)` |
| `date` | `XDate` | `bigint` | `date` | replaced by `date(ms)` |
| `time` | `LocalTime` | `int` | `number` | replaced by `time(ms)` |
| Type | Java | MySQL | JavaScript | Format |
|---|---|---|---|---|
| `localdate` | `LocalDate` | `char(10)` | `string` | `yyyy-MM-dd` |
| `localtime(s)` | `LocalTime` | `char(8)` | `string` | `HH:mm:ss` |
| `localtime(ms)` | `LocalTime` | `char(12)` | `string` | `HH:mm:ss.SSS` |
| `localtime(us)` | `LocalTime` | `char(15)` | `string` | `HH:mm:ss.SSSSSS` |
| `localdatetime(s)` | `LocalDateTime` | `char(19)` | `string` | `yyyy-MM-ddTHH:mm:ss` |
| `localdatetime(ms)` | `LocalDateTime` | `char(23)` | `string` | `yyyy-MM-ddTHH:mm:ss.SSS` |
| `localdatetime(us)` | `LocalDateTime` | `char(26)` | `string` | `yyyy-MM-ddTHH:mm:ss.SSSSSS` |
| Type | Java | MySQL | JavaScript | Notes |
|---|---|---|---|---|
| `localtime` | `LocalTime` | `char(12)` | `string` | replaced by `localtime(ms)` |
| `localdatetime` | `LocalDateTime` | `char(23)` | `string` | replaced by `localdatetime(ms)` |
| Type | Java | MySQL | JavaScript |
|---|---|---|---|
| `duration(s)` | `Duration` | `bigint` | `number` |
| `duration(ms)` | `Duration` | `bigint` | `number` |
| `duration(us)` | `Duration` | `bigint` | `number` |
| Type | Java | MySQL | JavaScript |
|---|---|---|---|
| `jsonarray` | `JsonArray` | `json` | `array` |
| `jsonobject` | `JsonObject` | `json` | `object` |
| ID | Name | Notes |
|---|---|---|
| `0` | `none` | default level, no associated formatting |
| `1` | `success` | green |
| `2` | `info` | cyan |
| `3` | `notice` | yellow |
| `4` | `warning` | red |
| `5` | `primary` | blue, elevated over `none` |
| `6` | `secondary` | grey, below `none` |
| ID | Name | Notes |
|---|---|---|
| `0` | `post` | |
| `1` | `task` | |
| `2` | `request` | request received |
| `3` | `response` | response to request received |
| ID | Name | Notes |
|---|---|---|
| `0` | `none` | default level, no associated formatting |
| `1` | `success` | green |
| `2` | `info` | cyan |
| `3` | `notice` | yellow |
| `4` | `warning` | red |
| `5` | `primary` | blue, elevated over `none` |
| `6` | `secondary` | grey, below `none` |
| Type | Java | MySQL | JavaScript | JSON |
|---|---|---|---|---|
| `null` | `null` | `NULL` | `null` | `null`, `""` (empty string) |